|
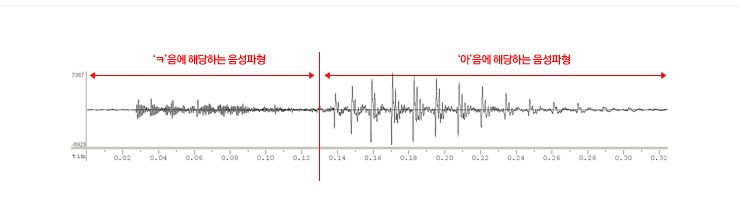
음성 인식을 위해서는 당연히 소리를 우선 들어야 하고, T 시간까지 발성된 음성이라면 이 음성은 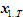 라고 쓰자. 다음 단계는, 어떤 말일까 예측을 해야 하는데 그 말이 몇 개의 단어로 되어 있는지 모르므로 라고 쓰자. 다음 단계는, 어떤 말일까 예측을 해야 하는데 그 말이 몇 개의 단어로 되어 있는지 모르므로 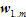 이라고 쓰고 여기서 m은 단어의 수가 된다. 첫 번째 식의 의미는, 음성이 주어졌을 때 모든 단어 조합에 대해서 가장 확률적으로 가능성이 큰 단어 열이 바로 우리가 찾고 싶은 단어 열이고 그것이 음성인식의 결과 이라고 쓰고 여기서 m은 단어의 수가 된다. 첫 번째 식의 의미는, 음성이 주어졌을 때 모든 단어 조합에 대해서 가장 확률적으로 가능성이 큰 단어 열이 바로 우리가 찾고 싶은 단어 열이고 그것이 음성인식의 결과 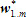 이라는 의미이다. 이라는 의미이다.
위에서 첫 번째 식은 베이즈 정리 (Bayes’ Theorem)에 의해서 두 번째 식이 되고, 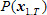 는 해당 음성 자체가 입력될 확률인데 이 값은 어떤 단어 열을 선택하든 언제나 분모로 있으므로 전체 식에 영향을 주지 않아 제거할 수 있다. 마지막 식에서 는 해당 음성 자체가 입력될 확률인데 이 값은 어떤 단어 열을 선택하든 언제나 분모로 있으므로 전체 식에 영향을 주지 않아 제거할 수 있다. 마지막 식에서 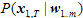 을 음향 모델(acoustic model)이라고 부르고 을 음향 모델(acoustic model)이라고 부르고 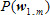 을 언어 모델(language model)이라고 부르는데, 이 두 모델의 확률 곱이 최대가 되는 이 우리가 찾고 싶은 최종 결과이다. 을 언어 모델(language model)이라고 부르는데, 이 두 모델의 확률 곱이 최대가 되는 이 우리가 찾고 싶은 최종 결과이다.
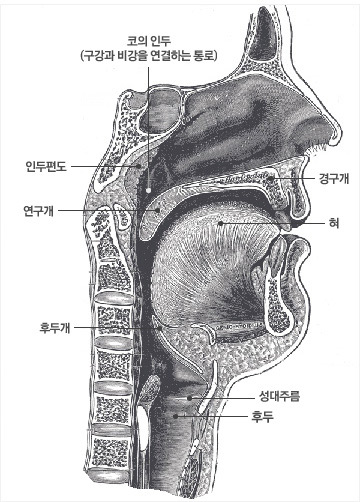
그럼, 두 모델의 의미는 무엇일까? 우선 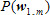 을 보면 음성 파형을 의미하는 가 없다. 즉, 파형을 보지도 않고 그 음성이 무엇일까 예측하는 확률이다. 예를 들어, 오늘이 올림픽 개최일이라고 가정하자. 그렇다면, 사람들은 아마도 ‘올림픽’이라는 단어를 사용할 가능성이 클 것이다. 그러므로 누군가 무슨 말을 했는데 그 말을 맞추어야 한다면, ‘올림픽’ 아니냐고 이야기하는 것이 가장 합리적인 생각일 것이다. 정리하면 을 보면 음성 파형을 의미하는 가 없다. 즉, 파형을 보지도 않고 그 음성이 무엇일까 예측하는 확률이다. 예를 들어, 오늘이 올림픽 개최일이라고 가정하자. 그렇다면, 사람들은 아마도 ‘올림픽’이라는 단어를 사용할 가능성이 클 것이다. 그러므로 누군가 무슨 말을 했는데 그 말을 맞추어야 한다면, ‘올림픽’ 아니냐고 이야기하는 것이 가장 합리적인 생각일 것이다. 정리하면 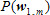 은 사람이 발화 시점에 어떤 단어들을 말할 확률을 미리 계산해서 가지고 있는 값이다. 두 번째로 은 단어 ‘올림픽’을 발성했을 때 해당 음성이 발성될 확률을 의미한다. 예를 들어 네 살배기 어린아이가 ‘올림픽’을 발성하는 것과 성인이 발성하는 것, 그리고 성우가 발성하는 것은 쉽게 생각해도 음의 명료성에서 크게 차이가 있을 것이다. 어린아이가 발성한 ‘올림픽’은 ‘올림’이 ‘우리’처럼 들려서 어쩌면 ‘우리 엄마’에 가깝게 들릴지도 모르고, 그러면 은 사람이 발화 시점에 어떤 단어들을 말할 확률을 미리 계산해서 가지고 있는 값이다. 두 번째로 은 단어 ‘올림픽’을 발성했을 때 해당 음성이 발성될 확률을 의미한다. 예를 들어 네 살배기 어린아이가 ‘올림픽’을 발성하는 것과 성인이 발성하는 것, 그리고 성우가 발성하는 것은 쉽게 생각해도 음의 명료성에서 크게 차이가 있을 것이다. 어린아이가 발성한 ‘올림픽’은 ‘올림’이 ‘우리’처럼 들려서 어쩌면 ‘우리 엄마’에 가깝게 들릴지도 모르고, 그러면 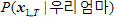 가 가 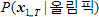 보다 더 높은 확률값을 가지게 된다. 보다 더 높은 확률값을 가지게 된다.
빠르게 인식하는 방법

위 음성 인식 수식을 보면, 모든 후보가 되는 단어 열에 대한 확률을 모두 구해야 하고 그 중 가장 높은 확률을 낸 단어 열을 선택하게 되어 있다. 한편, 단어 열 길이에 대해 제한이 없으므로, 상식적으로 생각해도 우리가 찾아야 하는 탐색 공간은 무한대가 되어 버린다. 그러므로 어떻게 빠르게 단어 열을 찾을 것인가가 중요한 문제가 된다. 이에 대한 해결책은 매우 단순하다. 모든 후보 단어 열에 대한 가능성을 열어두고 음성을 듣다가 정답이 아닐 것 같은 후보들을 탈락시키는 것이다. 마치 축구에서 토너먼트 경기를 하면서 한 팀씩 탈락하는 것처럼, 음성을 들으면서 가능성이 없는 후보는 빨리 탈락시킨다. 음성 신호가 모두 처리되었을 때는 그 험한 경쟁에서 살아남은 최종 승리자가 최종 인식 결과가 된다. |
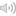






 English
English 한국어
한국어
